Python Crawler Example (1)
- 2 minsI found clicking on job posting website could be automized, so I wrote a script for crawling. Here I used Python, beautifulsoup, requests and generators tricks for practicing.
I used Salesforce Career Page for example.
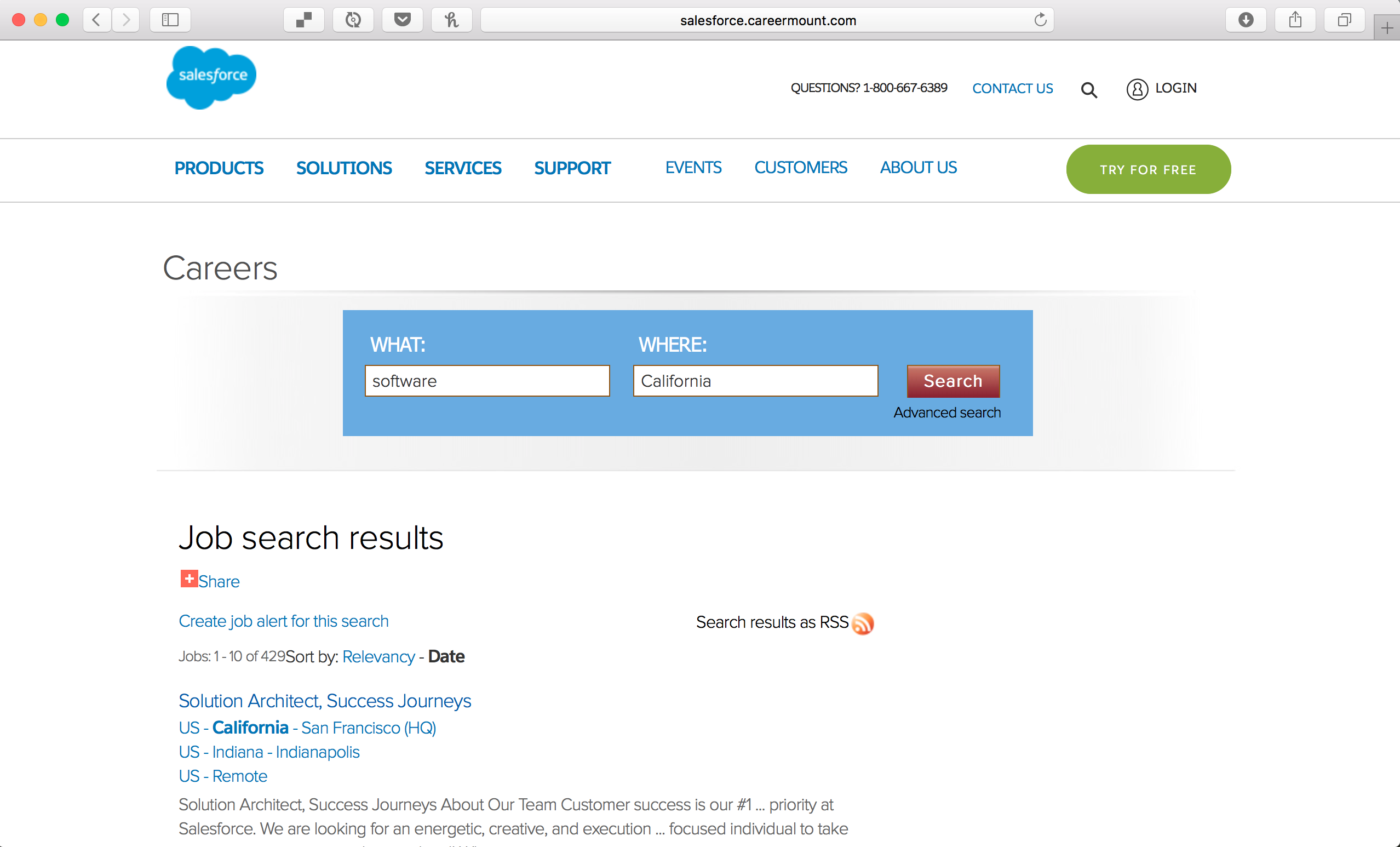
Where should I get started?
I knew Google Chrome has tool to see each request sent from browser, so I used that to see the request I sent from browser. By seeing that, I could know what kind of information I can wrap in code and issue a query.
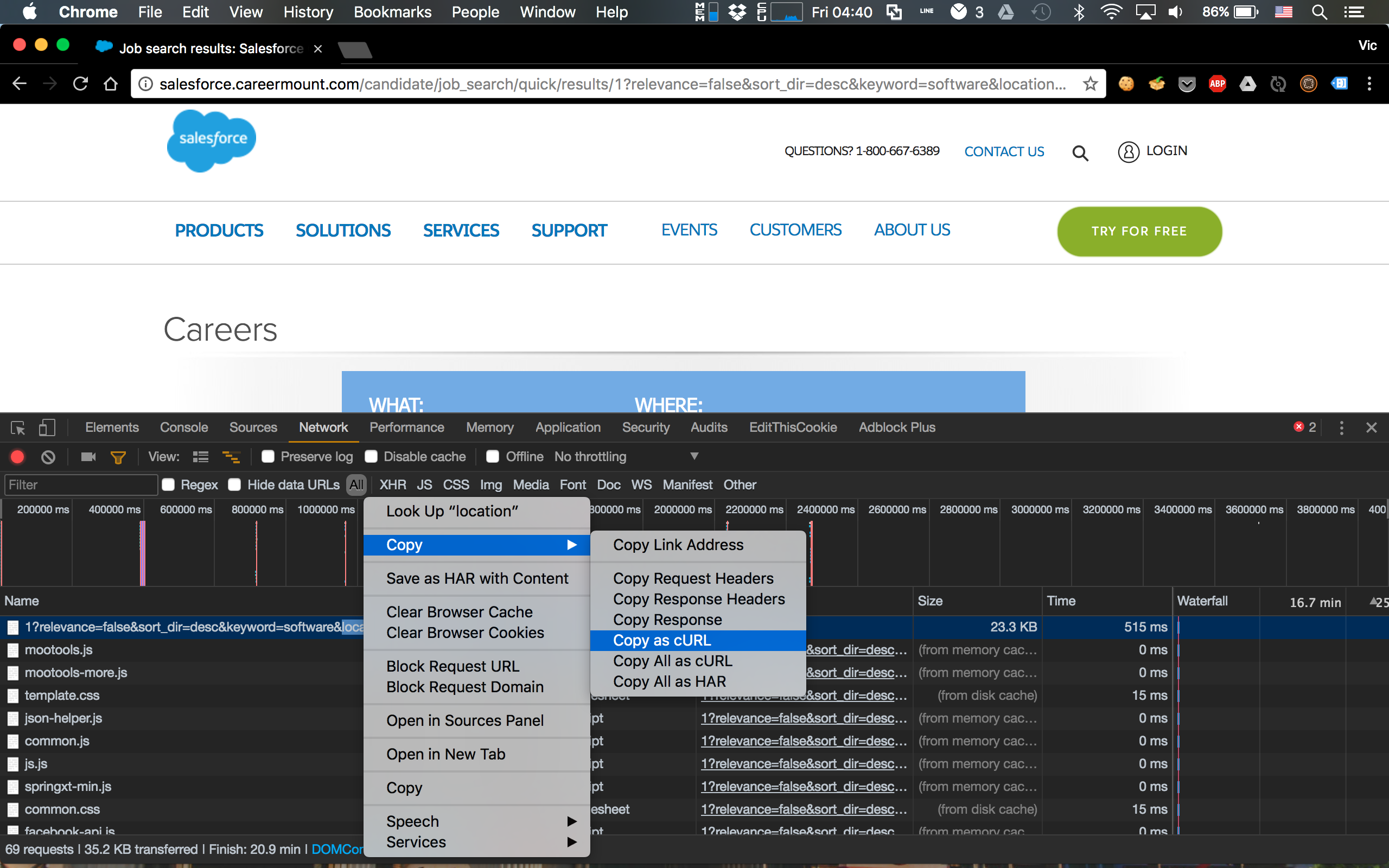
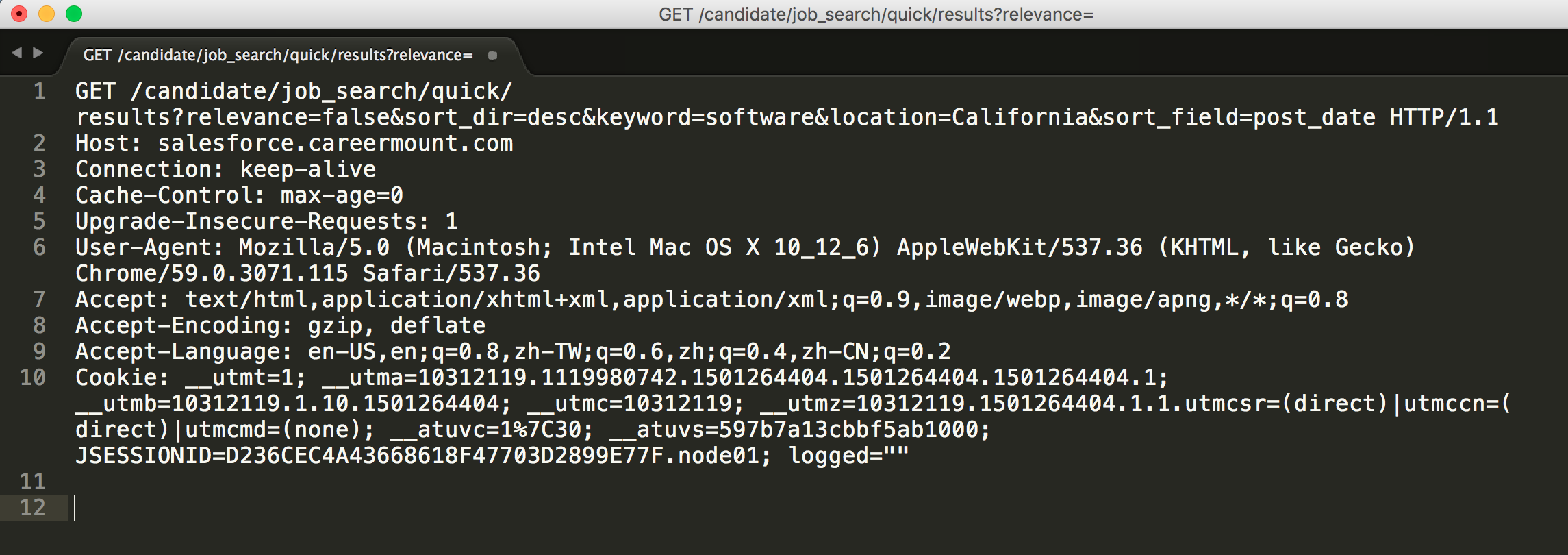
I pasted on editor and saw there was a GET request sent to Salesforce server. So, all I need is use requests to send a GET request to that and I can get the result.
Apply this code would receive 403. (HTTP Code 403 - Forbidden)
What happened then?
Apparently, it’s not enough for this request, so I guessed it required header information to send it.
And I received 200. (HTTP Code 200 - OK)
Start analyzing HTML
I put the response in BeautifulSoup and got parsed HTML. What I really need is the list of jobs. I observed that page from Chrome Developer Tool and found some important CSS tag.
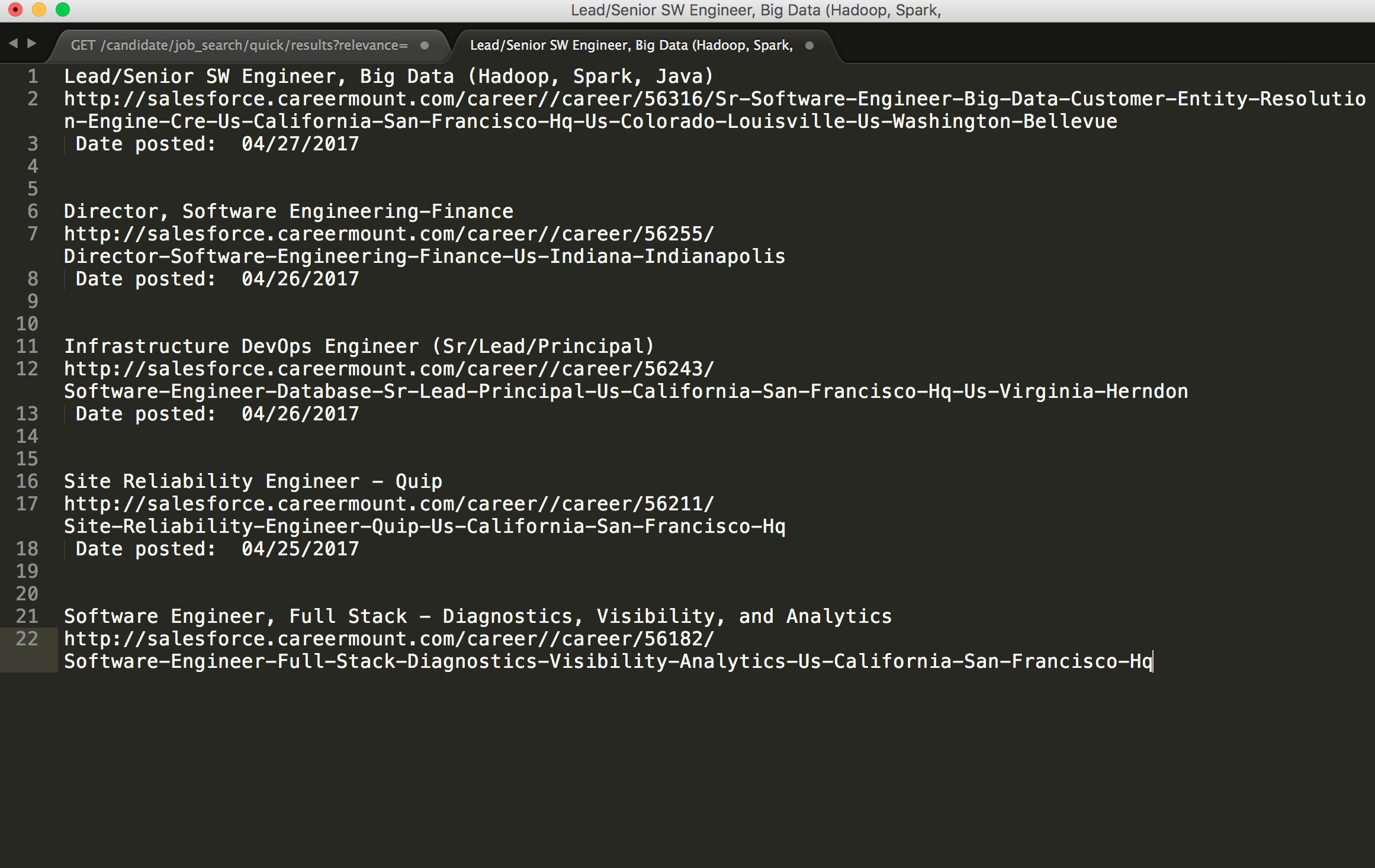
From this code, I got only 10 jobs listed on my terminal. There must be something wrong, and then I realized I only parsed one page.
Next part, I would use generator to generate different url.
Generate URL by leveraging generators
I composed a get_total_pages function to get total pages. I found it’s only 10 jobs listed on one page, so I used the jobnumbers divided by 10 and got the result.
The function is the logic of generator.
def url_cat(total_pages, url):
yield url
page = 1
while page <= total_pages:
yield url + str(page)
page += 1
I used 2 yield statements because the first url has no number concatenated afterward, and then I used the second yield to generate urls.
url_gen = url_cat(total_pages, url)
for url in url_gen:
soup = get_soup(url, headers, payload)
list_jobs(soup)
I applied for-loop to iterate the generator.
Now, I can get a list of information that I really wanted.
===
What’s inside?
- Python
- Generators
- Requests
- BeautifulSoup

Vic Yang
Back-end Engineer